- Mar 16, 2025
Context-Aware and High-Quality Cluster Summarization
- Chaomei Chen
A well-structured literature review is essential for making sense of a knowledge domain, whether it spans a specific research topic, an entire field, or multiple interrelated disciplines. A common approach involves identifying major concentrations of scholarly publications—clusters that emerge based on semantic, linguistic, ontological, and historical similarities.
However, a critical and cognitively demanding challenge remains: how do we synthesize these computationally identified clusters into meaningful insights? Understanding what is going on at a higher level requires an effective balance between automation and expert-level synthesis.
Updated: 7/22/2025
AI-Assisted Cluster Summarization in CiteSpace
CiteSpace has long supported cluster labeling and summarization, leveraging advances in Natural Language Processing (NLP) and, more recently, Large Language Models (LLMs). (See my previous blogs for earlier discussions on this topic.)
In a concept-proving experimental release of CiteSpace on March 12, 2025, we are making a significant step forward in improving AI-assisted cluster synthesis. The goal is to enhance the quality of summaries so they more closely resemble a well-written scholarly review article by a domain expert.
Basic Steps
Generate a network in CiteSpace. I highly recommend a network of co-cited references, aka a document co-citation analysis, for its values as concept symbols and specific contributions in a broad context.
Use the All-in-One function to divide the network into clusters and label clusters with CiteSpace built-in labeling methods.
Double check settings for GPT-labeling and summarization such as the language for the output and any adjustments of the default settings for your specific situation such as the API rate limit. These options are under the menu Clusters > GPT.
Start the process with the GPT button on the tool bar. It has a light green background.
It usually takes a few seconds to complete, but we may feel much longer than it is. You can check its status in the command line console. You will see something like the following. When you see the line completed, then it is done.

Now the cluster labels in the display should be already switched to the labels that the GPT came up with. You can re-run the GPT function but choose to use existing labels to display labels stored from the most recent run. If you need to refresh the labels altogether, you can choose the other option.
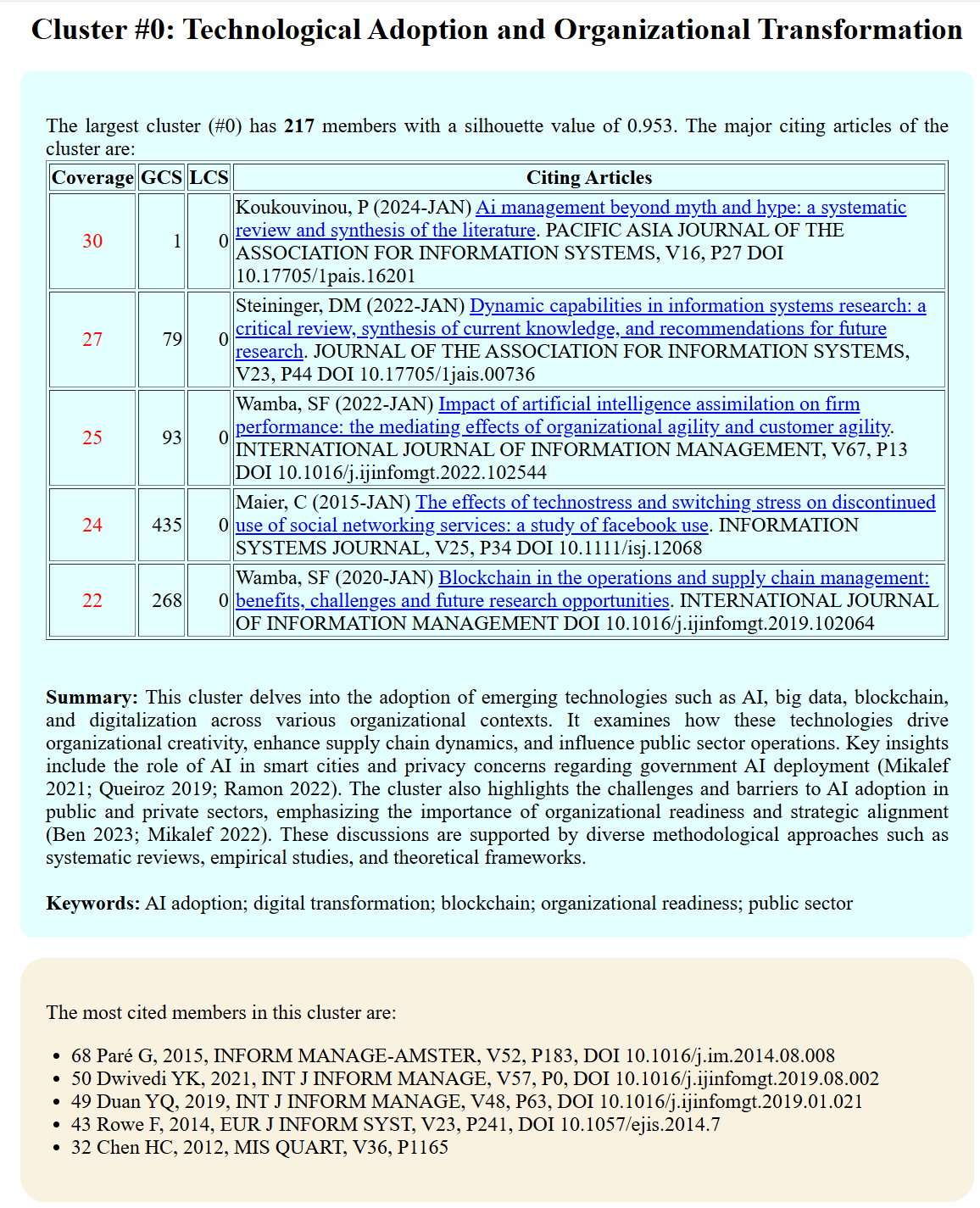
Follow the menu Summary > Summary Report, you will see the summaries among other information. The summary of each cluster consists a few parts. First, it shows a table of 5 citing articles to the cluster that have the highest coverage in terms of the number of members in the cluster they cite. In this illustrative example, the first citing article cited 30 members of the cluster out of a total of 217.
The actual summary follows the citing article table. Then, a list of keywords. Finally, a table of cited articles.
What's Old
The previous implementation of cluster labeling and summarization using LLMs like GPT-4 had a notable limitation:
Cluster labels may overlap or overly broad because they were generated independently for each cluster, leading to similar names across distinct clusters.
Summaries lacked meaningful contextualization, making it difficult to understand how key themes connected to specific scholarly works.
To address this, we have integrated GPT-4o via OpenAI’s API into CiteSpace. Looking ahead, I anticipate that future versions of CiteSpace will offer additional cost-efficient, high-quality AI models for enhanced literature review support.
What's New
1. Unique and Context-Aware Cluster Labels
The new implementation ensures that each cluster label is unique and meaningful by considering all clusters simultaneously when generating labels. This eliminates overlapping or overly generic labels, resulting in a clearer and more distinct taxonomy of research themes.
2. Scholarly Citation-Integrated Summaries
The enhanced cluster summarization process incorporates citations directly into the summary.
Key articles cited within the dataset are referenced using ALA-style in-text citations, providing direct connections between summarization points and supporting literature.
This context-aware synthesis follows the way a human expert would construct a review, ensuring that each summary is both data-driven and interpretatively rich.
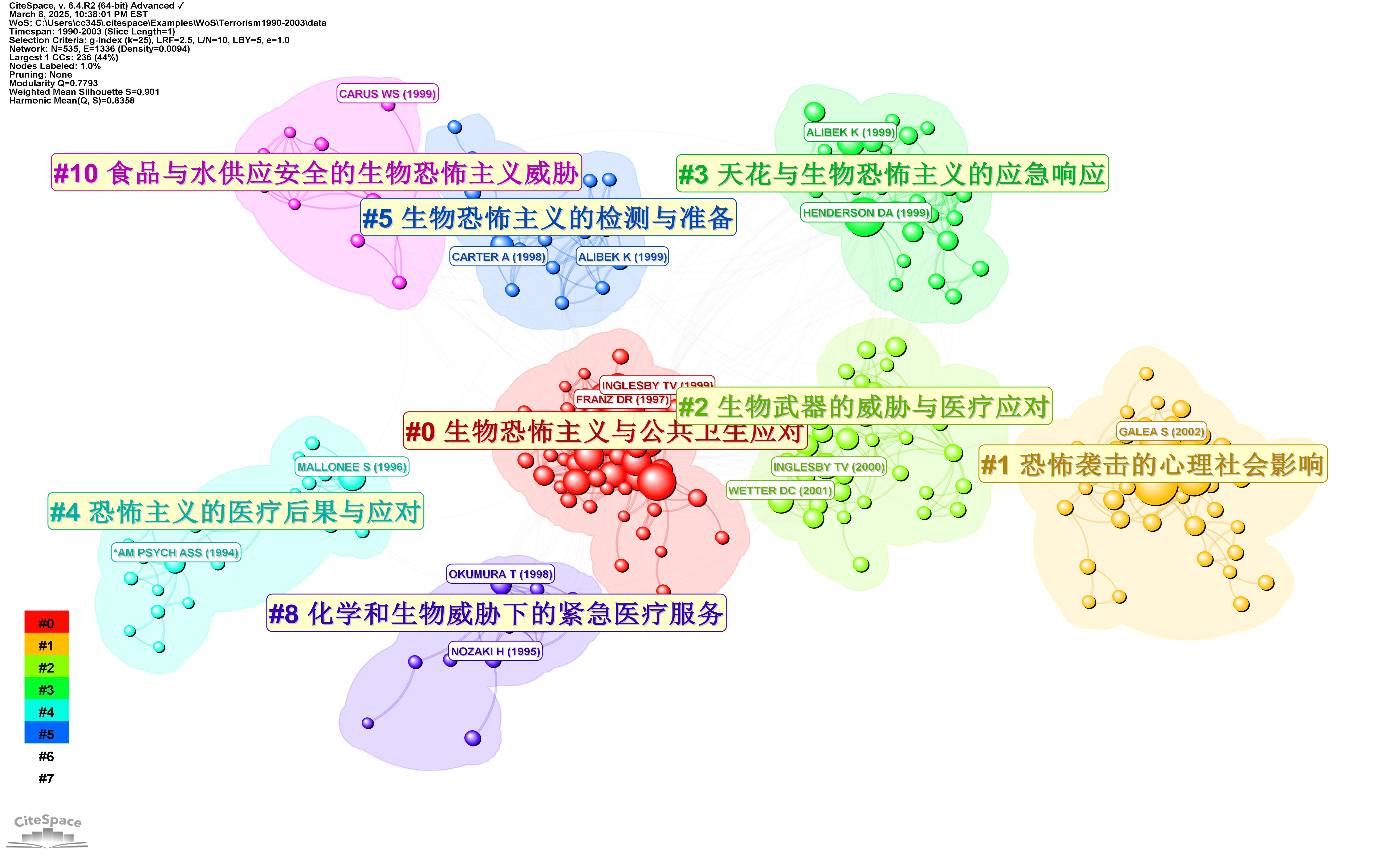
Example: Terrorism Research Project
To illustrate, the built-in Terrorism Research project in CiteSpace now generates:
Distinct cluster labels—each capturing a unique research theme.
Summaries enriched with scholarly citations, ensuring precise and well-supported thematic synthesis.
A list of keywords suggested by GPT-4o, further refining the conceptual structure of each cluster.
This new approach significantly enhances the readability, coherence, and usability of cluster summaries, enabling researchers to quickly grasp the landscape of their field and identify key works for further reading.
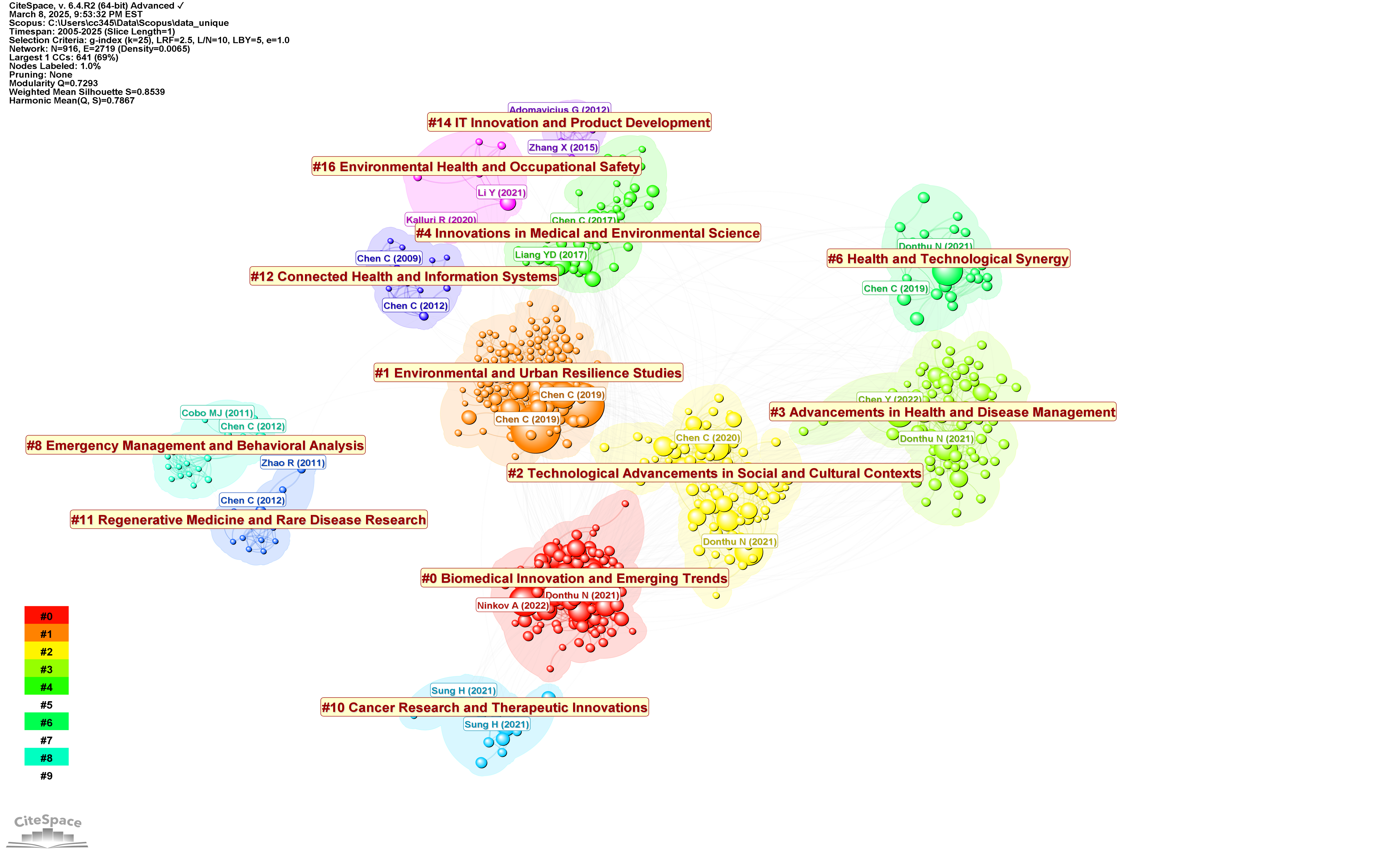
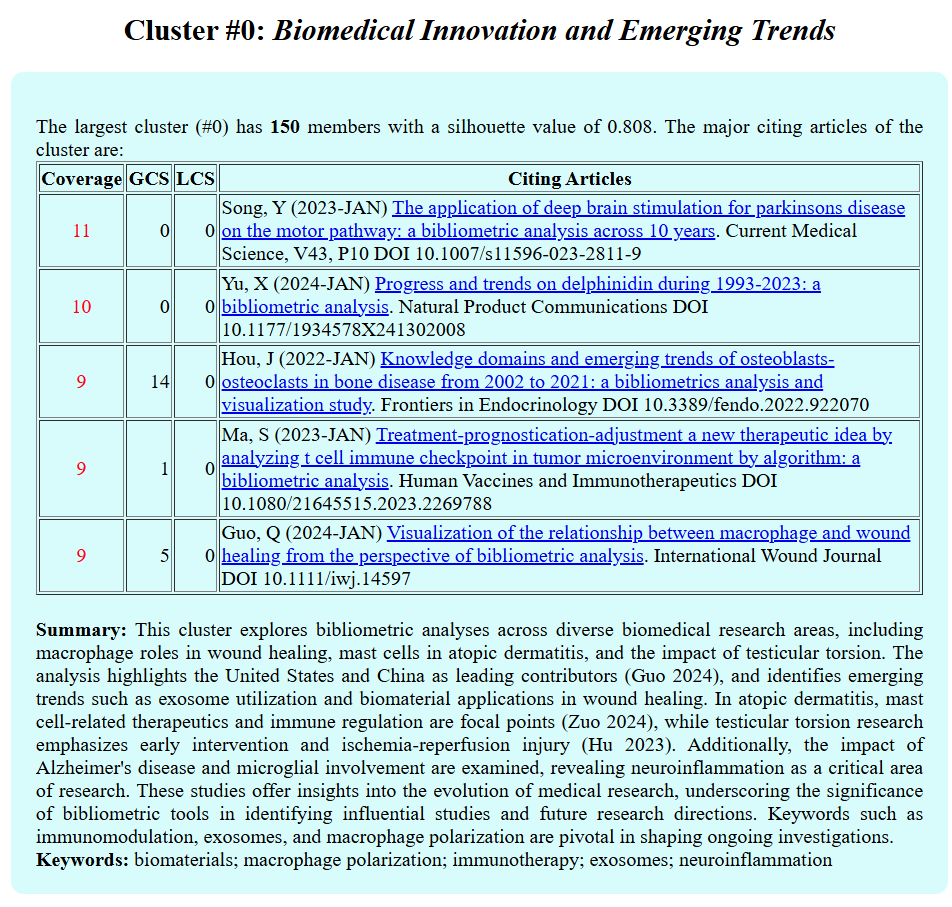
The new version of a cluster summary highlights key themes along with citations to specific and highly cited citing articles (wordy but precise) to support the summarization points. These cited articles provide convenient stepping stones for further and deeper exploration of the cluster.
A list of keywords is also provided by gtp-4o.


Future Developments
While GPT-4o has significantly improved cluster summarization, there are still factors to consider:
Cost Efficiency: The overall computational cost is influenced by the number of tokens processed.
Scalability: Large-scale analyses with many large clusters require careful optimization to balance detail vs. cost.
Expanded Model Support: Future versions of CiteSpace may integrate additional LLM options to provide more flexibility in balancing cost, accuracy, and detail level.
My long-term vision is to enable AI-assisted literature reviews to match the quality of expert-written synthesis, helping researchers work more efficiently and gain deeper insights.
Try it out and share your experience!